Figure 3


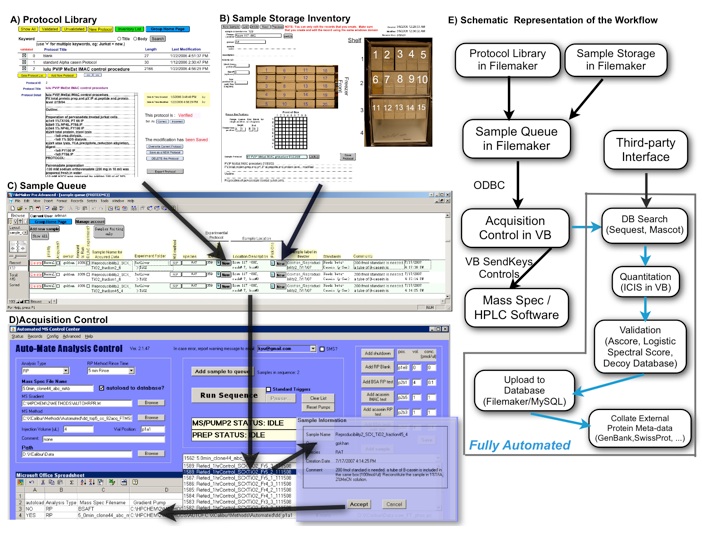
Figure 3. Integration among relational database component, data acquisition control, and fully autonomous post-acquisition analysis of HTAPP. A) A sample-generating user enters the protocol used in sample creation, B) the location of the sample, and any critical post-acquisition parameters into a C) sample queue located within our FileMaker database. D) The mass spectrometer operator then selects the sample for analysis with the acquisition control software component of our integrated system, which resides on the mass spectrometer control computer. All preferences for post-acquisition analysis, such as database search parameters and quantitation choices, are passed automatically to the acquisition control software from the sample queue and may be optionally modified by the instrument operator. When ‘run sequence’ is clicked, the acquisition control software communicates directly with data acquisition software provided by the instrument manufacturers via flexible VB SendKeys controls. E) Immediately after data acquisition is complete, the acquisition control software initiates automated data analysis, including MS/MS database searching, quantitation of relative peptide abundance, validation of peptide sequence assignments, loading of resulting data into FileMaker/MySQL, and caching of relationships between newly collected proteomic data and existing protein knowledge imported from external protein information databases and located internally within FileMaker/MySQL.